
nov 16, 2020
Para una atención médica justa y equitativa, necesitamos que la IA aplicada a este propósito sea justa y libre de sesgos
La inteligencia artificial (IA) tiene el potencial de hacer que la atención médica sea más accesible, asequible y efectiva, pero también puede conducir inadvertidamente a conclusiones erróneas y, por lo tanto, puede amplificar las desigualdades existentes. La mitigación de estos riesgos requiere que se tenga conciencia del sesgo que puede colarse en los algoritmos de IA, y cómo prevenirlo a través de un diseño e implementación cuidadosos. En un estudio ampliamente divulgado publicado en Science el año pasado, un grupo de investigadores de la Universidad de California reveló que un algoritmo utilizado por los hospitales estadounidenses que permite identificar a los pacientes de alto riesgo para una mayor atención médica mostró un sesgo racial significativo. Los pacientes afroamericanos eran menos propensos a ser identificados para recibir atención adicional comparado con los pacientes blancos, incluso cuando estaban igualmente enfermos [1]. Técnicamente, no había nada de malo con el algoritmo y sus creadores nunca tuvieron la intención de discriminar a nadie. De hecho, diseñaron el algoritmo para que no considerara características raciales. Entonces, ¿qué causó el sesgo? El problema con el algoritmo era que predecía los costos futuros de atención médica, en lugar de la enfermedad futura, para identificar a los pacientes de alto riesgo que necesitan atención adicional. Dado que los pacientes afroamericanos en los EE. UU. en promedio tienden a tener un acceso más limitado a la atención médica de alta calidad, por lo general incurren en costos más bajos que los pacientes blancos con las mismas condiciones. Por lo tanto, depender de los costos de atención médica como una característica representativa de los riesgos para la salud y las necesidades de atención médica coloca a los pacientes afroamericanos en una desventaja considerable. Cuando los investigadores realizaron una simulación con los datos clínicos en su lugar, el porcentaje de personas referidas para recibir atención médica adicional que eran afroamericanas aumentó de 17.7 a 46.5% [i]. Este estudio destaca cómo las disparidades arraigadas en los sistemas de salud pueden ser reforzadas involuntariamente por los algoritmos de IA.
Con un diseño cuidadoso, la IA promete crear un futuro más saludable y justo para todos. Pero también existe el riesgo de que terminemos codificando las desigualdades actuales y pasadas.
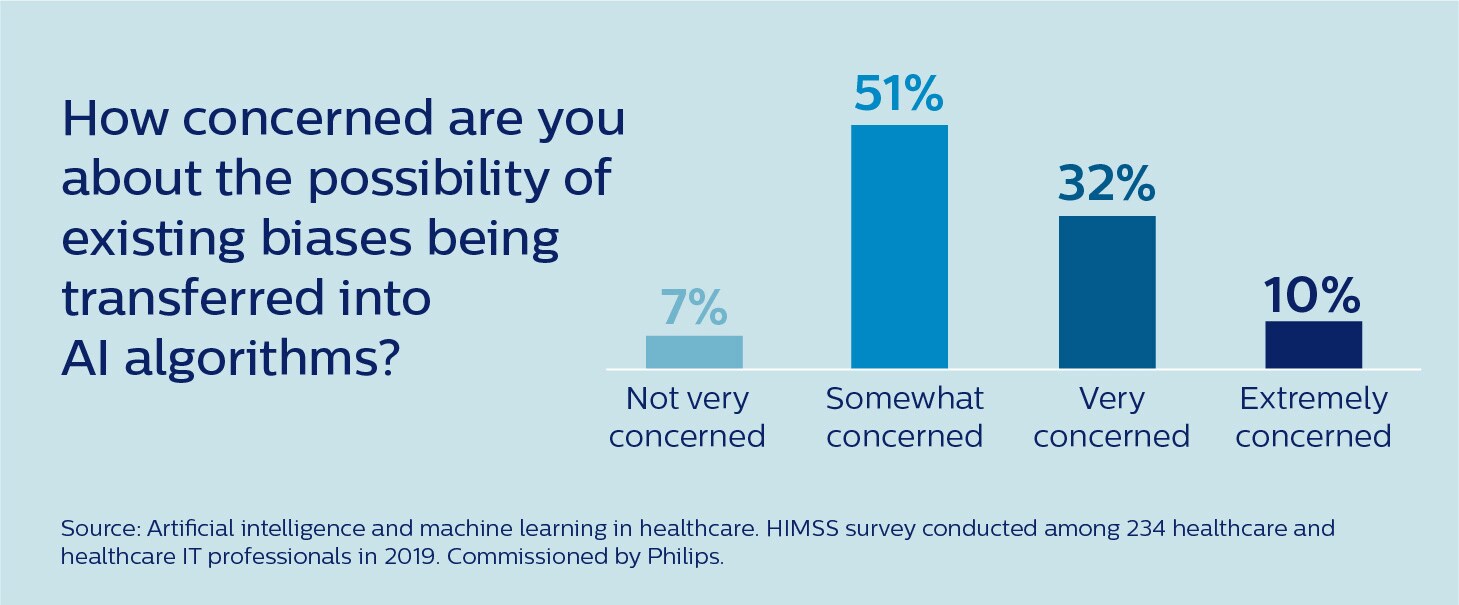
Es un riesgo que ya es bien reconocido en la comunidad de cuidado de la salud. Según una encuesta reciente realizada por la Healthcare Information and Management Systems Society (HIMSS), el 93 % de los profesionales de cuidado de la salud y de TI de salud están al menos algo preocupados de que los sesgos existentes puedan transferirse a algoritmos de IA [2].
Entonces, ¿cómo podemos asegurar que la IA sea justa y ayude a reducir las disparidades de salud existentes en lugar de exacerbarlas?
¿Cómo puede surgir el sesgo en la IA?
Para mitigar eficazmente el riesgo de sesgo en la IA en la atención de la salud, primero debemos entender las diferentes maneras en que puede surgir. Podría decirse que el mayor escollo en el desarrollo y la implementación de la IA es que aceptamos su producción sin criticar y sin examinar suficientemente sus aportaciones y opciones de diseño subyacentes. Es un fenómeno psicológico bien documentado que las personas tienden a aceptar las recomendaciones con base en computadoras a valor nominal [3]. Los algoritmos de IA proporcionan una capa de objetividad y de imparcialidad a cualquier proceso de toma de decisiones. Sin embargo, la verdad es que la salida de un algoritmo está en gran medida moldeada por los datos que alimentamos en este, y por otras opciones humanas que guían el desarrollo y la implementación del algoritmo. Estas opciones pueden estar sujetas a sesgos que involuntariamente ponen a ciertos grupos en una desventaja.
Podría decirse que el mayor obstáculo en el desarrollo y la implementación de la IA es que aceptamos su producción sin criticar y sin examinar suficientemente sus aportaciones y opciones de diseño subyacentes.
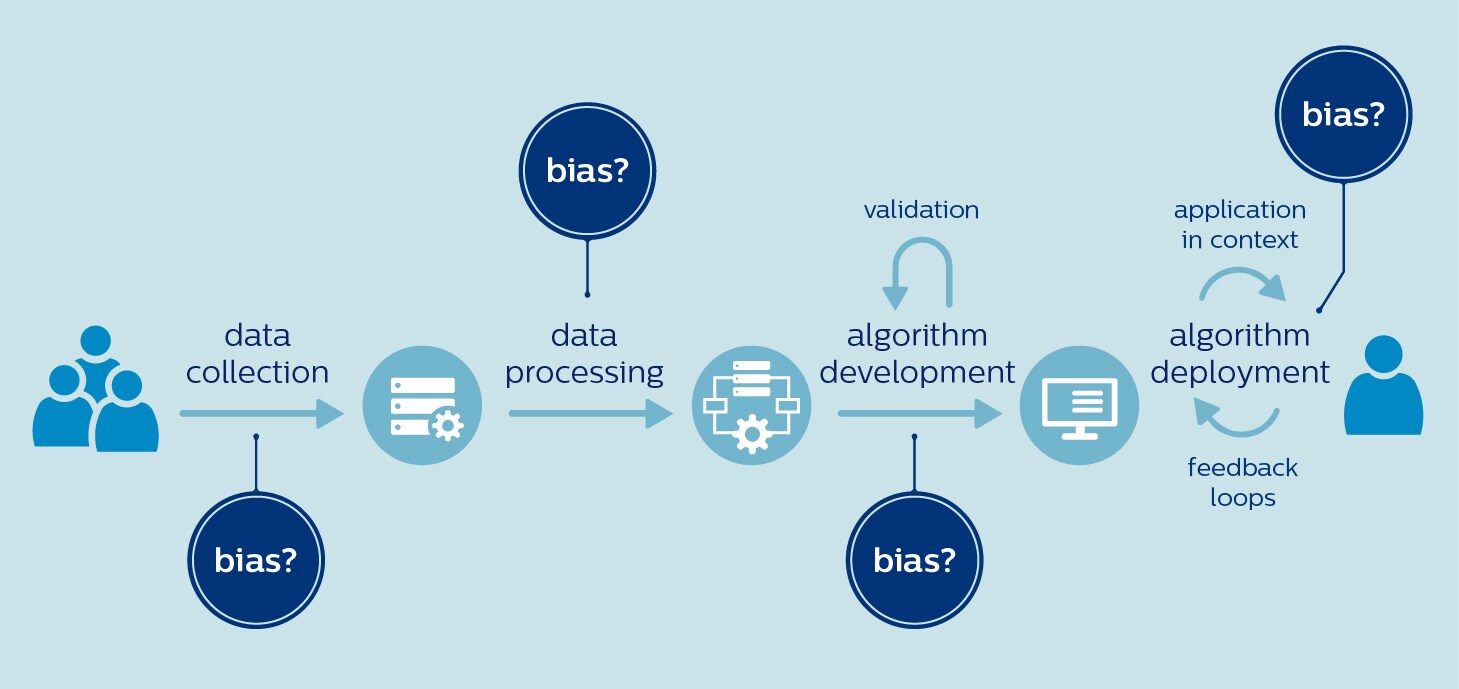
En el sector del cuidado de la salud, existe un alto riesgo de sesgo desde el principio, cuando se seleccionan los datos para entrenar un algoritmo. Esto se debe a que los conjuntos de datos disponibles podrían no ser representativos de la población objetivo. Por ejemplo, las mujeres y los afroamericanos están evidentemente subrepresentadas en los ensayos clínicos [4,5]. La investigación genómica también tiene un largo camino por recorrer para lograr una mayor inclusividad, con un 81 % de los participantes de ascendencia europea [6]. Con los datos sesgados surge el peligro de una IA sesgada. Los investigadores han planteado preocupaciones de que los algoritmos que analizan imágenes de la piel podrían pasar por alto melanomas malignos en personas de color, ya que estos algoritmos están entrenados predominantemente en imágenes de pacientes blancos [7]. Del mismo modo, algunos han cuestionado si los algoritmos diseñados para priorizar la atención a los pacientes con COVID-19 realmente están aumentando la carga de morbilidad en las poblaciones desatendidas [8]. Si estas poblaciones carecen de acceso a las pruebas de COVID-19, los algoritmos pueden no tomar en cuenta sus necesidades y características porque están subrepresentados en los datos de entrenamiento. Las opciones seleccionadas durante el procesamiento de datos y el desarrollo de algoritmos también pueden contribuir al sesgo, incluso si los datos en sí están libres de sesgo. Por ejemplo, las diferencias relevantes entre las poblaciones podrían pasarse por alto en la búsqueda de un modelo único. Sabemos que muchas enfermedades se presentan de manera diferente en hombres y mujeres, ya sea por enfermedad cardiovascular, diabetes o trastornos de salud mental como la depresión y el autismo. Si los algoritmos no toman en cuenta esas diferencias, podrían magnificar las desigualdades de género existentes [9]. Por último, es importante darse cuenta de que lo que es justo e inclusivo en un contexto, no lo es necesariamente en otro. Un ejemplo revelador es un algoritmo que fue desarrollado en un hospital de Washington para anotar informes de pacientes con cáncer con resultados de pruebas basados en las notas de los médicos. El algoritmo funcionó muy bien en el hospital de Washington. Pero cuando este se aplicó en un hospital de Kentucky, su rendimiento se desplomó. ¿Cuál fue la causa? Los médicos de Kentucky usaron diferentes terminologías en sus notas [10]. En resumen, el sesgo podría producirse en cualquier fase del desarrollo e implementación de IA, desde el uso de conjuntos de datos sesgados hasta la implementación de los algoritmos en un contexto diferente para el que se entrenó para:
Entonces, la pregunta es qué podemos hacer al respecto.
Adoptar la equidad como un principio rector
Los organismos públicos y reguladores, así como los actores privados de la industria, han reconocido la necesidad de principios y políticas rectores claros para prevenir el sesgo en la IA. En un intento por promover el uso beneficioso y responsable de IA, la Comisión Europea estableció un Grupo de expertos de alto nivel (HLEG) que ha publicado directrices sobre IA confiables, incluyendo "diversidad, no discriminación y equidad". En Estados Unidos, se ha propuesto la Ley de responsabilidad algorítmica, que requeriría que las empresas evalúen sus sistemas de IA en busca de riesgos de tomar decisiones injustas, sesgadas o discriminatorias. Y en China, la Administración Nacional de Productos Médicos (NMPA) publicó recientemente una nueva normativa [en chino] para controlar el riesgo de sesgo en los dispositivos médicos. En Philips, hemos adoptado la justicia como uno de nuestros cinco principios rectores para el uso responsable de IA. Creemos que las soluciones habilitadas para IA se deben desarrollar y validar con datos representativos del grupo objetivo para el uso previsto, evitando al mismo tiempo sesgos y discriminación.
La justicia debe ser un principio rector para el uso responsable de la IA.
Por supuesto, los principios son igual de valiosos que las prácticas que los respaldan. Debido a que muchas de las posibles fuentes de sesgo están fuertemente incorporadas en los datos de salud actuales, que reflejan las desigualdades históricas y socioeconómicas, debemos superar grandes desafíos como industria. De hecho, la mayoría de estos desafíos no son específicos de IA y la ciencia de datos: piden que se hagan cambios más amplios y sistémicos, como mejorar el acceso a la atención para los desfavorecidos y hacer que la investigación médica sea más inclusiva. Cuando se trata de IA y ciencia de datos específicamente, se requiere de mayor conciencia de cómo puede surgir el sesgo en varias etapas del desarrollo de algoritmos y cómo se puede mitigar. Esto comienza con la capacitación y la educación. Además, necesitamos desarrollar sistemas de gestión de calidad sólidos para monitorear y documentar el propósito, la calidad de los datos, el proceso de desarrollo y el rendimiento de un algoritmo. Y, tal vez aún más importante, necesitamos construir diversidad en todos los aspectos del desarrollo de IA.
Tres tipos de diversidad que son importantes
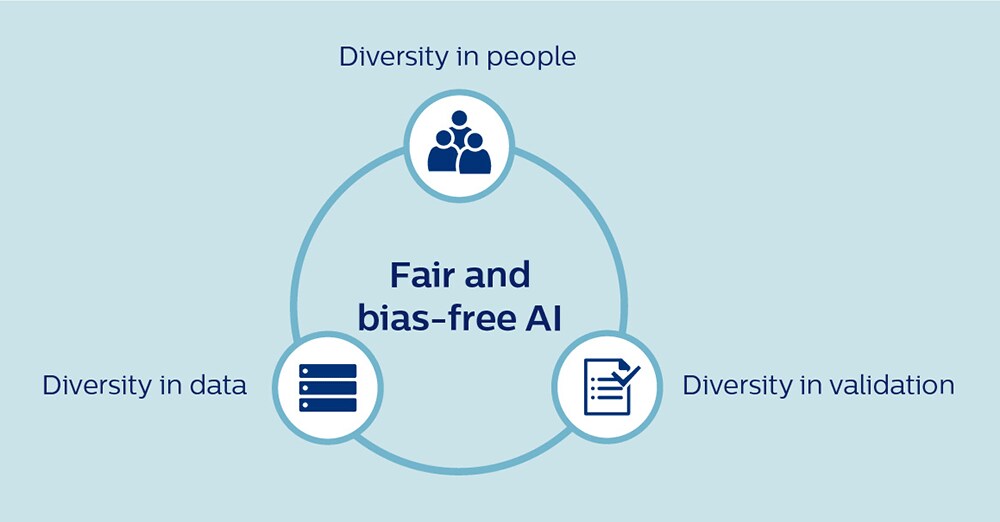
Hay tres tipos de diversidad que son fundamentales para crear una IA justa: diversidad en las personas, diversidad en los datos y diversidad en la validación. Permítanme profundizar brevemente en cada uno de estos.
1. Diversidad en las personas En primer lugar, para hacer que la IA esté libre de prejuicios y sea beneficiosa para todos, es esencial que las personas que trabajan en IA reflejen la diversidad del mundo en el que vivimos. En un campo que por lo general ha estado dominado por desarrolladores masculinos blancos, debemos hacer todo lo posible para fomentar una cultura más inclusiva. En Philips, recientemente aumentamos nuestros compromisos con la diversidad de género en puestos de liderazgo sénior y, en el mismo espíritu, la inclusión y la diversidad (ya sea en cuanto a género, etnia o formación profesional) serán una prioridad para nosotros a medida que continuamos ampliando nuestras capacidades en IA y ciencia de datos. Igualmente, importante es que promovamos una intensa colaboración entre los desarrolladores de IA y expertos clínicos para combinar las capacidades de IA con una profunda comprensión contextual del cuidado de la salud. Por ejemplo, cuando se conocen las diferencias en la manifestación de la enfermedad entre hombres y mujeres o diferentes grupos étnicos, los médicos pueden ayudar a validar si las recomendaciones algorítmicas no perjudican inadvertidamente a grupos específicos. Para complementar aún mejor esa experiencia, los estadísticos y metodólogos con un profundo conocimiento del sesgo y las estrategias de mitigación adecuadas son otro activo vital para los equipos de desarrollo de IA. Solamente mediante una verdadera cooperación multidisciplinar podremos aprovechar las fortalezas de los demás y compensar nuestros puntos ciegos individuales.

2. Diversidad en los datos La disponibilidad limitada de los datos (de alta calidad) puede ser un obstáculo importante en el desarrollo de la IA que represente con precisión a la población objetivo. Para promover el desarrollo de una IA justa y sin prejuicios, debemos aspirar a agregar conjuntos de datos más grandes, bien anotados y seleccionados en todas las instituciones, de una manera segura y confiable que proteja la privacidad del paciente. Por ejemplo, Philips estableció el Instituto de Investigación eICU de Philips como una plataforma para avanzar en el conocimiento de la atención crítica mediante la recopilación de datos no identificados de más de 400 participantes de ICU en los Estados Unidos. El repositorio de datos se ha utilizado para desarrollar herramientas de IA para atención crítica, incluido un algoritmo que ayuda a decidir si un paciente está listo para ser dado de alta de la UCI. En el contexto de COVID-19, los investigadores también han pedido un intercambio más amplio de los datos de los pacientes entre instituciones e incluso países para asegurar que los algoritmos de apoyo a la toma de decisiones clínicas se desarrollen a partir de conjuntos de datos diversos y representativos, en lugar de muestras de conveniencia limitadas en centros médicos académicos [8]. 3. Diversidad en la validación Una vez que se ha desarrollado un algoritmo, se requiere una validación exhaustiva para asegurarse de que funciona con precisión en toda la población objetivo, y no solo en un subconjunto de esa población. Los algoritmos podrían necesitar un reentrenamiento y recalibración cuando se aplican a los pacientes de diferentes países o etnias, o incluso cuando se utilizan en diferentes hospitales en el mismo país. De manera alentadora, hemos observado en nuestra propia investigación basada en el repositorio de datos de eICU que los algoritmos derivados de hospitales tienden a generalizarse bien a otros hospitales estadounidenses no incluidos en el conjunto de datos original. Pero siempre se requiere de un escrutinio cuidadoso. Por ejemplo, cuando probamos algunos de nuestros algoritmos de investigación eICU desarrollados por Estados Unidos en China e India, descubrimos que era necesario realizar un reentrenamiento local. Debido a que el riesgo de sesgo debe ser controlado cuidadosamente, también necesitamos contar con fuertes protectores en torno al uso de la IA de autoaprendizaje. Un algoritmo se puede validar cuidadosamente para el uso previsto antes de su introducción al mercado, pero ¿qué pasa si continúa aprendiendo de nuevos datos en los hospitales donde se implementa? ¿Cómo nos aseguramos de que el sesgo no se introduzca inadvertidamente? Como también han reconocido los reguladores, será necesario un monitoreo continuo para garantizar un rendimiento justo y sin sesgos.
Un futuro más justo para todos
Falta mucho trabajo por hacer, pero creo que con una diversidad adecuada en las personas, los datos y la validación, respaldados por sólidos sistemas de gestión de la calidad y procesos de monitoreo, podemos mitigar con éxito el riesgo de sesgo en la IA. Aún mejor, ¿podríamos hacer que la atención sanitaria sea más justa al adaptar los algoritmos a poblaciones específicas de pacientes, incluidos los grupos históricamente desfavorecidos o subrepresentados?
¿Podríamos hacer que la atención sanitaria sea más justa al adaptar los algoritmos a poblaciones específicas de pacientes, incluidos los grupos históricamente desfavorecidos o subrepresentados?
Por ejemplo, al saber que tradicionalmente no se ha hecho la suficiente investigación sobre las enfermedades coronarias, ni se ha diagnosticado o tratado a las mujeres adecuadamente [11], ¿podríamos desarrollar algoritmos que estén específicamente orientados a detectar o predecir las manifestaciones femeninas de la enfermedad? En una era de medicina de precisión, en la que estamos pasando cada vez más de un enfoque único a un enfoque personalizado del cuidado de la salud, es una vía interesante para la investigación adicional, que por supuesto debe respetar plenamente los límites éticos, legales y reglamentarios en torno al uso de datos personales confidenciales. En el futuro, puedo imaginar que será posible ajustar un algoritmo a una población específica del paciente objetivo para obtener un rendimiento óptimo y sin sesgos. Esto podría ser otro paso hacia un futuro más justo e inclusivo para el cuidado de la salud, respaldado por la IA que no solo reconoce la variación entre los diferentes grupos de pacientes, sino que está diseñado para capturarla. Referencias [1] Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366, 447–45. https://doi.org/10.1126/science.aax2342 [2] HIMSS (2019), a solicitud de Philips. Artificial intelligence and machine learning in healthcare. Encuesta realizada entre 234 encuestados en organizaciones de la salud de Estados Unidos. [3] Goddard, K., Roudsari, A., & Wyatt, J. (2012). Automation bias: a systematic review of frequency, effect mediators, and mitigators. JAMIA, 19(1), 121–127. https://doi.org/10.1136/amiajnl-2011-000089 [4] Feldman, S., Ammar, W., Lo, K., et al. (2019). Quantifying sex bias in clinical studies at scale with automated data extraction. JAMA, 2(7): e196700. https://doi.org/10.1001/jamanetworkopen.2019.6700 [5] Redwood, S., & Gill, P.S. (2013). Under-representation of minority ethnic groups in research - call for action.Br J Gen Pract. 63(612): 342-343. https://doi.org/10.3399/bjgp13X668456 [6] Popejoy, A., & Fullerton, S. (2016). Genomics is failing on diversity. Nature, 538(7624):161-164http://doi.org/10.1038/538161a [7] Adamson, A., & Smith, A. (2018). Machine learning and health care disparities in dermatology. JAMA Dermatology. 154(11):1247–1248. https://doi.org/10.1001/jamadermatol.2018.2348 [8] Röösli, E., Rice, B., & Hernandez-Boussard, T. (2020). Bias at warp speed: how AI may contribute to the disparities gap in the time of COVID-19. JAMIA, ocaa210. https://doi.org/10.1093/jamia/ocaa210 [9] Cirillo, D., Catuara-Solarz, S., Morey, C. et al. (2020). Sex and gender differences and biases in artificial intelligence for biomedicine and healthcare. npj Digit. Med. 3, 81. https://doi.org/10.1038/s41746-020-0288-5 [10] Goulart, B., Silgard, E., Baik, C. et al. (2019). Validity of natural language processing for ascertainment of EGFR and ALK test results in SEER cases of Stage IV Non-Small-Cell Lung Cancer. Journal of Clinical Cancer Informatics. 3:1-15. https://doi.org/10.1200/CCI.18.00098 [11] Mikhail G. W. (2005). Coronary heart disease in women. BMJ (Clinical research ed.), 331(7515), 467–468.https://doi.org/10.1136/bmj.331.7515.467 Notas: [i] Con base en su análisis, los investigadores posteriormente comenzaron a trabajar junto con los desarrolladores del algoritmo para reducir el sesgo racial
Comparta en sus redes sociales
Temas
Autor

Henk van Houten
Former Chief Technology Officer at Royal Philips from 2016 to 2022
Más noticias relacionadas
-
![Philips publica su Informe Anual 2024]()
febrero 21, 2025
-
![Resultados del cuarto trimestre y anuales de Philips 2024]()
febrero 19, 2025
-
![10 tendencias en tecnología sanitaria para 2025]()
febrero 05, 2025
-
![Acceso equitativo a la atención médica para las madres y los niños]()
febrero 04, 2025
-
![Philips anuncia nuevo liderazgo en América Latina]()
febrero 03, 2025



